Journal of Applied Pharmacy
Open Access
ISSN: 1920-4159
ISSN: 1920-4159
Research Article - (2018) Volume 10, Issue 1
This study is concerned about prediction of dissolution rate of Insoluble drugs from solid dispersion (SD) polymer matrixes by an Adaptive Neuro-Fuzzy Inference System (ANFIS). Polyethylene Glycols (PEGs) as the SD with different molecular weights were provided and dissolution rate of indomethacin (IND) was obtained experimentally. A USP dissolution method was used to monitor the dissolution profiles of matrixes. The numbers of rules were trained in a systematic procedure using the experimental data. Comparison of IND dissolution rate from different matrixes, Area under the Curve (AUC) of absorbance vs. time diagrams in the first 25 min for 72 different samples was determined. Results show a high correlation between observed and predicted data (r2=0.85). The calculated root mean square error for the results of the ANFIS model is equal to 1.02. The index of area AUC in the first 25 min is more repeatable. It seems that the model has practical value and different ratios of polymer for the desired dissolution rate can be predicted or having different polymer ratios in the matrix can predict the dissolution rate of IND. this method can be suggested for other pharmaceuticals formulations to save time and money to achieve the best formula.
<Keywords: Indomethacin; Dissolution rate; Matrix; Neuro-fuzzy; PEG
SD: Solid Dispersion; ANFIS: Adaptive Neuro-Fuzzy Inference System; PEGs: Polyethylene Glycols; IND: Indomethacin; NSAID: Non-Steroidal Anti-Inflammatory Drug; ANNs: Artificial Neural Networks; AUC: Area Under the Curve; MFs: Membership Functions; RSME: Root Mean Square Error
Indomethacin (IND), a non-steroidal anti-inflammatory drug (NSAID) is used as pain/swelling reduction drug involved in diseases such as osteoarthritis, enclosing spondylitis, and headaches [1]. IND is known as practically insoluble in water and highly permeable (Class II) drug [2]. For the purpose of developing the drug preparations, enhancement of dissolution rate and solubility are important, because water-insoluble drugs often show low adsorption and poor bioavailability [3]. IND shows low and erratic oral bioavailability due to poor dissolution in the fluids of the gastrointestinal tract. Formulation development of poorly water-soluble drugs is one of the major problems in pharmaceutical manufacturing. Additionally, the undesirable physical property of IND and also a prolonged contact time between IND and the mucosa may increase the incidence of irritating side effects on the gastrointestinal tract [4].
During the last decades, several techniques have been studied to enhance the dissolution rate in development of drug formulations, to increase adsorption such as; using adsorbents, surfactant, hydrotropes and co-solvents, liquid-solid compacts, fast releasing micro particles, interactive mixtures, solid dispersion (SD) [5,6].
SD is a technique used in a limited number of researches to increase the solubility and dissolution rate of IND [7]. The SD technique provides an efficient solu tion to improve the dissolution rate of a drug [8]. This technique is defined as the dispersion of one or more active ingredients in inert carriers (matrix) at solid state such as crystalline, solubilized or amorphous state [9,10]. It has been widely utilized to enhance the dissolution rate, solubility and oral adsorption of poorly water-soluble drugs [11-13]. There are some advantages in this technique that drug dissolution was improved markedly such as reduce in particle size of the drug, the wettability and the dispensability were enhanced [14-16].
Polyethylene glycols (PEGs) are polymers that place among the several carriers which have been employed in preparing SD [7]. It has a lot of applications in pharmaceutical formulations to prepare fast and sustained release formula. PEGs are widely applied for their special properties such as low melting point, low toxicity, wide drug compatibility and hydrophobicity [7,15,17-20].
There are theoretical models proposed to describe the drug release behavior. The Adaptive Neuro-Fuzzy Inference System (ANFIS) would be proper for prediction in science and technology, particularly drug releasing. The theory of fuzzy sets was introduced and categorized [21,22]. Fuzzy logic is a useful method for systems involved in complex issues which make challenges for many studies like evaluating and predicting. Fuzzy system is able to implement human language, it can also use individual experiences to progress [23,24]. Moreover, artificial networks are capable of learning. Artificial neural networks (ANNs) was introduced by McCulloch-Pitts in 1940s [25]. They showed that ANNs can compute any logical function. ANNs have made this possible by modeling the connections of human brain neurons. The ability of them in discovering the complex relations between input and output data and establishing a non-linear dynamic model is significant. Nevertheless, ANNs has a black box nature and cannot show a systematic procedure between inputs and outputs. Merging fuzzy logic and artificial neural networks was a bridge to overcome this weakness. For the first time, the self-learning capability of neural networks and fuzzy systems simultaneously was suggested by Jang in 1993 [26]. These systems were known as ANFIS.
This study is about the dissolution rates of IND from different ratio of PEGs, predicting by computational method and comparison with experimental data [27].
Preparation of PEGs matrix of IND
PEGs matrix are prepared by melting the physical mixture of PEGs in different ratios and different molecular weights (2000, 4000, 6000 and 20000) at 55°C with stirring. Besides that, IND was dissolved in molten mixture (5.375% W/W). Subsequently the solution was poured in molds and cooled down at room temperature.
Dissolution test
A USP dissolution apparatus 2 (paddle method) (Pharmatest, Germany) was used to monitor the dissolution profiles of matrixes. Each dissolution vessel was filled with 900 ml dissolution media (0.1 M phosphate buffer pH 7.2) at 37°C and 50 rpm.
Samples were taken from the vessels at selected time intervals through sintered filter by a peristaltic pump (Alitea, Sweden), and the concentration of IND in the samples assayed at 318 nm by a multi-cell changer spectrophotometer (Shimadzu, Japan) based on a calibration curve obtained for IND at this wavelength. The dissolution of each sample was determined in triplicate.
In order to comparison of IND dissolution rate from different matrixes, Area under the Curve (AUC) of absorbance vs. time diagrams in the first 25 min for 72 different samples was determined (shaded area). Figure 1 shows a sample diagram of Absorbance vs. time. Table 1 shows the few samples out of 72 total samples.
| PEG 2000 | PEG 4000 | PEG 6000 | PEG 20000 | AUC (0-25 min) |
|---|---|---|---|---|
| 0 | 0 | 0 | 100 | 4.62 |
| 0 | 65 | 35 | 0 | 7.31 |
| 0 | 30 | 45 | 25 | 3.12 |
| 30 | 0 | 0 | 70 | 6.53 |
| 10 | 20 | 45 | 25 | 9.43 |
| 25 | 15 | 40 | 20 | 13.01 |
| 50 | 10 | 10 | 30 | 14.83 |
| 55 | 20 | 15 | 10 | 16.38 |
| 65 | 15 | 10 | 10 | 16.46 |
| 85 | 5 | 5 | 5 | 21.35 |
Table 1: Ten samples out of 72 experiments.

Figure 1: Solubility diagram of IND from (PEG 2000, PEG 4000, PEG 6000 and PEG 20000 (0%, 0%, 100% and 0% respectively).
These samples are extracted from experiments done to investigate the combination of four compounds achieving AUC.
Due to the cost of experiments and taking long time a mathematical model is introduced to eliminate these two problems. This is achieved applying the experimental data. It leads to determine the AUC of the new combination without doing any experiments. In the next section the way of discovering this model is explained (Figure 2).

Figure 2: The amount of AUC for all experiments.
Design and training of a fuzzy inference system for prediction of dissolution rate
This section, a fuzzy model is employed to predict the proposed properties. Figure 3 shows the fuzzy structure. In middle layers, rules have been built using ANFIS model learning. Figure 4 illustrates the basic structure of the ANFIS algorithm.

Figure 3: General fuzzy structure [22].

Figure 4: Basic ANFIS structure [22].
A Sugeno model was employed with four inputs, after which a Takagi–Sugeno type fuzzy IF–THEN rules was used (Eqn. 1).
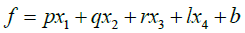 (1)
(1)
x1, x2, x3 and x4 are inputs 1 through 4 respectively and p, q, r and l are their coefficients, b is the bias value and f is the output value of the fuzzy logic system. The first layer of this model was contained the input variable membership functions (MFs). This layer arranged the input to the next layer. In the first layer, each node was provided as an adaptive node with an independent function, 1, Ol,i = μ(i) where μ(i) are MFs (Here the output of the ith node in layer l is denoted as Ol,i).
 (2)
(2)

Where x1 (x2, x3 or x4) is the input to node i and Pi (Qi−4, Ei−8 or Ri−12) is a linguistic label belong to this node. In other words, Ol,i is the membership grade of a fuzzy set P and it determines the degree to which the given input x1 (x2, x3 or x4) satisfies the quantifier P. Tri-shaped MFs with a maximum value equals to 1 and a minimum value equals to 0 were selected according to (Eqn. 3).
 (3)
(3)
The parameters {a, b, c} (with a

Figure 5: Fuzzy membership functions for inputs.
The second layer named membership layer allocate to the weights for each membership function. This layer multiplies the related signals and directs them as shown in (Eqn. 4).
 (4)
(4)
Each node output represented the firing strength (wi) of a rule. In fact, operators that perform fuzzy AND can be used as the node fuction in this layer. The nonlinear parameters in this layer are identified by the gradient descent method.
The third layer creates rules so it is named as ruler layer. Each node calculated normalized weights. Normalized firing strengths (w*i) are computed as shown in (Eqn. 5).
 (5)
(5)
Difuzzifying is running in the fourth layer using the inference of the rules and then outputs are generated as shown in (Eqn. 6).
 (6)
(6)
Variables are w*i from layer 3 and {Pi, Qi, Ei, Ri, Gi}. These linear parameters identified by back propagation and a least-squares estimation.
The final layer combined all of difuzzified input and calculated the output as the aggregated of all incoming signals as shown in (Eqn. 7).
 (7)
(7)
Using this methodology, the learning algorithm is employed to identify the parameters. ANFIS applied back propagation learning to specify the parameters getting the membership functions related and least mean square estimation to determine the consequent parameters [28,29].
In order to determine how data fit the proposed fuzzy model, the coefficient of determination (R2), correlation coefficient and Root Mean Square Error (RSME) were employed. If data set consists of n data members labeled with y1 … yn and the predicted data are labeled with f1 … fn, then, the mean of observed data is calculated by (Eqn. 8).
 (8)
(8)
The variability of the data set is given using two summations, first total sum of squares as shown in (Eqn. 9).
 (9)
(9)
Second, sum of squared residuals are calculated by (Eqn. 10).
 (10)
(10)
Then, the coefficient of determination is calculated using (Eqn. 11).
 (11)
(11)
Root mean square error can be calculated by (Eqn. 12).
 (12)
(12)
Numerical results (ANFIS)
The number of rules are 44=256 trained in a systematic procedure using the experimental data. For this fuzzy system some rules are as the following (Table 2):
| 1. If (PEG-2000(g/mol) is in1mf1) and (PEG_4000(g/mol) is in2mf1) and (PEG_6000(g/mol) is in3mf1) and (PEG_20000(g/mol) is in4mf1) then (AUC is out1mf1) (1) |
| 2. If (PEG-2000(g/mol) is in1mf1) and (PEG_4000(g/mol) is in2mf1) and (PEG_6000(g/mol) is in3mf1) and (PEG_20000(g/mol) is in4mf2) then (AUC is out1mf2) (1) |
| 3. If (PEG-2000(g/mol) is in1mf1) and (PEG_4000(g/mol) is in2mf1) and (PEG_6000(g/mol) is in3mf1) and (PEG_20000(g/mol) is in4mf3) then (AUC is out1mf3) (1) |
| 4. If (PEG-2000(g/mol) is in1mf1) and (PEG_4000(g/mol) is in2mf1) and (PEG_6000(g/mol) is in3mf2) and (PEG_20000(g/mol) is in4mf1) then (AUC is out1mf4) (1) |
| 5. If (PEG-2000(g/mol) is in1mf1) and (PEG_4000(g/mol) is in2mf1) and (PEG_6000(g/mol) is in3mf2) and (PEG_20000(g/mol) is in4mf2) then (AUC is out1mf5) (1) |
| 6. If (PEG-2000(g/mol) is in1mf1) and (PEG_4000(g/mol) is in2mf1) and (PEG_6000(g/mol) is in3mf2) and (PEG_20000(g/mol) is in4mf3) then (AUC is out1mf6) (1) |
| 7. If (PEG-2000(g/mol) is in1mf1) and (PEG_4000(g/mol) is in2mf1) and (PEG_6000(g/mol) is in3mf3) and (PEG_20000(g/mol) is in4mf1) then (AUC is out1mf7) (1) |
| ……. 255. If (PEG-2000(g/ml) is in1mf4) and (PEG-4000(g/ml) is in2mf4) and (PEG-6000(g/ml) is in3mf4) and (PEG-20000(g/ml) is in4mf3) then (AUC is out1mf255) (1) 256. If (PEG-2000(g/ml) is in1mf4) and (PEG-4000(g/ml) is in2mf4) and (PEG-6000(g/ml) is in3mf4) and (PEG-20000(g/ml) is in4mf4) then (AUC is out1mf256) (1) |
Table 2: Some rules of fuzzy system.
The performance of the mathematical model for training is displayed in Figures 6 and 7.

Figure 6: Comparison of theoretical and experimental results for the training results.

Figure 7: Results achieved by ANFIS.
As discussed before, fuzzy model were designed to predict the AUC in the proposed different molecular weights of PEGs.
Figure 8 shows the importance and sensitivity of the components regarding achieved AUC, respectively. The results extracted from fuzzy model are pictured for different inputs versus the other inputs. The result is displayed by a color bar placed at the right hand of each graph. As it is clear these results are only the reagent of real AUC not the accurate results.

Figure 8: Coefficient of determination (R2) and regression line for created ANFIS model.
These graphical results show the binary effects of PEGs in AUC. For instance, it can be seen from the Figure 7 (D) which compares the PEGs with molecular weights of 4000 and 6000 (g/mol), using simultaneously PEG with molecular weights of 4000 higher than 90% and PEG with molecular weights of 6000 lower than 15% in drug combination leads to higher AUC.
Evaluation of ANFIS model
The calculated correlation coefficients for these results of ANFIS model are demonstrated in Table 3 and RMSE is equal to 1.02. It is obvious that the model with R2 value closer to 1 is a better model for prediction of system’s behavior. As indicated in Figure 8 this model showed R2=85%, promising to consider a reliable model for predicting this proposed property. Meanwhile to show the predictors clearly a regression line was fitted to all of observed and predicted data. Moreover, the comparison of the theoretical and the experimental results in other format is displayed in Figure 9.
| 2000 | 4000 | 6000 | 20000 | AUC | |
|---|---|---|---|---|---|
| 2000 | 1 | -0.54447 | 0.024696 | -0.25467 | -0.31846 |
| 4000 | -0.54447 | 1 | -0.4962 | -0.18869 | 0.301172 |
| 6000 | 0.024696 | -0.4962 | 1 | -0.50211 | -0.20982 |
| 20000 | -0.25467 | -0.18869 | -0.50211 | 1 | 0.086986 |
| AUC | -0.31846 | 0.301172 | -0.20982 | 0.086986 | 1 |
Table 3: Correlation coefficients for created ANFIS model.

Figure 9: Comparison of theoretical and experimental results.
The results of this study showed the index of area under the curve comparison with the slope (dissolution rate) in the first 25 min more repeatable. Therefore, the area under the curve (amount of IND dissolved in 25 min) was used as an index of the dissolution rate. Evaluation of ANFIS model showed the significant fit of the results predicted by the model was mentioned. It seems that the model has practical value and different ratios of polymer for the desired dissolution rate can be predicted or having different polymer ratios in the matrix can predict the dissoulution rate of IND. We suggested this method for other pharmaceutical formulations to save the time and the money to achieve the best formula.
We thank Dr. Masoud Goharimanesh (Department of Mechanical Engineering, Ferdowsi University of Mashhad) and Parisa Tavakkoli (Sun Air Research Institute, Ferdowsi University of Mashhad) for their valuable discussions. The authors appreciate the Research Council of Mashhad University of Medical Sciences (MUMS) for the financial support.