Journal of Theoretical & Computational Science
Open Access
ISSN: 2376-130X
ISSN: 2376-130X
Research Article - (2024)Volume 10, Issue 3
This paper proposes an approach for the automatic extraction of direct quotes from texts using Large Language Models (LLMs) and their analysis to build semantic networks of authors and concepts. After retrieving relevant documents, LLMs are employed to extract quotes, their authors and metadata, which are stored in a structured JavaScript Object Notation (JSON) format. Based on this data, a semantic network is constructed, which is then clustered using LLMs. The concept of a "swarm of virtual experts" is introduced for more precise extraction of key concepts. The model illustrates how authors form groups based on shared interests and discussion topics. One of the innovative aspects of the approach is the automatic generation of cluster names.
Quote extraction; Semantic network; Clustering; Swarm of virtual experts; Automatic text analysis; Large Language Models (LLM)
Today, a large volume of textual information contains important fragments of direct speech, including interviews, public speeches and statements from prominent figures. Automatic extraction of these fragments is significant for content analysis, media monitoring and studying social trends.
The development of LLMs has significantly transformed approaches to text data processing. Automated analysis of large text corpora, particularly the extraction of direct quotes, has become increasingly important, allowing for rapid retrieval of information from speeches, interviews and publications. As a result of LLMs, the process of extraction and subsequent analysis is faster, more accurate and scalable.
In this work, we propose a methodology based on the use of LLMs for the automatic extraction of quotes and the construction of networks of authors and key concepts. An important task following the extraction of quotes is the identification of key concepts related to the quotes and the creation of semantic networks of authors and concepts. These networks can be clustered, which helps in identifying groups of authors discussing similar topics. We propose using the "swarm of virtual experts" concept, where LLMs are queried multiple times about key concepts, each time simulating different expert roles to enhance analysis results. The goal of the research is to develop a process for analyzing direct quotes and identifying thematic connections between different authors.
The problem of extracting direct quotes and their subsequent analysis has been discussed in many studies. One of the main challenges is the accurate identification of the boundaries of direct speech, especially in complex texts such as news articles, interviews or legal documents. Some research focuses on traditional Natural Language Processing (NLP) methods, such as using regular expressions, parsers and semantic analyzers for quote extraction. However, LLMs significantly simplify this task by better interpreting the context of quotes and tracking relevant segments [1-4].
Another important area is the construction of semantic networks, where concepts and authors represent graph nodes and the connections between them are edges. Semantic networks are used to study collaboration in science, media analysis, political communication and other domains. Clustering such networks helps expose hidden thematic structures and shared interests. Clustering methods, such as the modularity algorithm, are used to group graph nodes by common properties [5-8].
The proposed concept of the "swarm of virtual experts" is similar to approaches using model ensembles and multiple queries [9]. It improves accuracy by generating a "family" of queries from different hypothetical experts, each modeling different perspectives on the same text.
Document retrieval stage
Initially, documents are retrieved using an information retrieval system based on specific keywords related to the chosen topic. The retrieved documents must be suitable for direct quote analysis.
Quote and author extraction
LLMs are employed to extract fragments of direct speech (quotes) from the text. Based on prompts, quotes, author names, publication dates and source URLs are extracted. This data is stored in a JSON format, which includes:
{
"title":"TitleoftheArticle",
"url":"LinktotheArticle",
"date":"PublicationDate",
"Citations":[
{
"author":"AuthorName",
"Citations":[
"Quote1"
"Quote2"
"Quote3"
]
},
{
"author":"AuthorName2",
"citations":[
"Quote1",
"Quote2"
]
}
]
}
Semantic analysis and network construction
For each author, after the extraction of quotes, the LLM performs the extraction of key concepts that form the semantic network. The concept of a "swarm of virtual experts" is proposed-this involves multiple queries to the LLM, each simulating an expert with different roles, such as sociologist, politician, journalist etc. This approach helps better account for context and show more connections between concepts.
Quote extraction stage
Let D = {d1,d2,..dn} be the set of documents retrieved from the search system, where each document did_idi contains a set of textual data. We can consider the LLM as a function that takes the text of a document and returns a set of author-quote pairs in Equation (1).
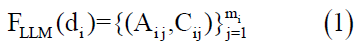
Where Aij is the author of the j-th quote in document di, Cij is the text of the direct speech or quote from author, mi is the number of quotes in document di.For all documents, we obtain the set of all quotes in Equation (2)
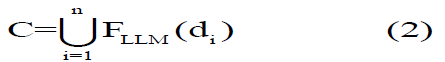
At this stage, the LLM should identify authors and their direct quotes within the text. The prompt should include a request to find quotes and authors in the document.
Semantic network construction stage
Next, each quote Cij is analyzed to extract key concepts. Let Fconcepts (Cij) be the keyword extraction function that returns the set of concepts Kij for each quote in Equation (3).
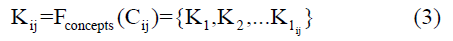
Where lij is the number of key concepts for quote Cij. Thus, for all quotes, a bimodal network is constructed with two types of nodes: authors A and concepts K. A node Aij is connected to a concept Kp if that concept was extracted from quote Cij. Formally, this can be represented as a graph G=(V,E), where V and E represented in Equations (4 and 5).

is the set of nodes (authors and concepts),
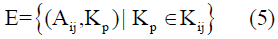
is the set of edges between authors and their concepts.
Network clustering
Modularity algorithms allow for the grouping of authors based on thematic similarity. LLMs can also perform network clustering based on modularity and autonomously determine cluster names by analyzing common concepts within them.
The modularity of the network is calculated using the Equation (6):
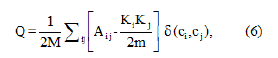
Where Aij is the element of the adjacency matrix, ki and kj are the degrees of nodes i and j , m is the number of edges and ä (ci,cj) is a function that equals 1 if nodes i and j belong to the same cluster.
Cluster naming stage
For each cluster Ci that contains authors A1, A2-Ap and concepts K1, K2-Kq, the LLM can generate a name based on the most significant concepts within the cluster. The selection of these concepts can be made by evaluating their weight in the cluster based on their frequency or centrality in the network.
Let the weight of concept Kj in cluster Ci be defined by the Equation (7)
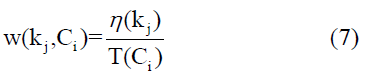
Where η(kj) - number of connections of concept kj Tη(kj) - total number of connections in cluster Ci.
After determining the weights of the most influential concepts, the LLM can generate a cluster name based on these key terms.
Example of usage
As a result of analyzing texts using the proposed method, a dataset of documents related to cyber security was examined. Based on the extracted quotes, a semantic network was constructed, containing over 50 authors and 200 concepts (Figure 1).

Figure 1: Fragment of the clustered network.
Here are examples of authors and quotes.
{
"title": "Yoon reaffirms Seoul's commitment to global cybersecurity cooperation",
"url": "https://www.koreatimes.co.kr/www2/common/viewpage.asp?newsIdx=382368&categoryCode=205",
"date": "2024-09-11T10:47:00T",
"citations": [
{ "author": "Yoon Suk Yeol ", "citations": [
"South Korea has long been a stronghold in cybersecurity, developing its defense capabilities and security systems in response to cyberattacks from hostile forces, including North Korea. We will actively contribute to protecting humanity's safety and prosperity by sharing our capabilities and experiences with the world.",
"Countries around the world are shifting towards 'active cybersecurity' based on international solidarity. South Korea also announced its national cybersecurity strategy in February this year, enhancing its proactive defense capabilities to respond preemptively to cyber threats and is making concerted efforts to collaborate internationally against transnational cyber threats.",
"South Korea plans to deepen its cooperation with NATO and reaffirmed his commitment to enhancing cybersecurity collaboration with the alliance."
]
}
]
}
This technology opens up new opportunities for automated quote analysis, particularly in large text corpora. The use of a "swarm of virtual experts" to refine concepts enhances the results of the analysis. Automated clustering and cluster naming provide greater context for analyzing thematic groups.
The implementation of direct speech extraction technology can be integrated into a large information and analytical system, with two possible approaches. The first approach involves adding extraction results to each document in a retrospective database, allowing for direct searching within quotes. This global approach requires setting up a dedicated LLM implementation for such a system, offering advantages in flexibility and control over text processing but complicating the use of rapidly evolving LLM models.
The second approach involves using extraction technology and semantic network construction in real-time, only for documents relevant to the user's query. In this case, the retrospective database is not indexed at the quote level and searching within direct quotes is not possible, but this approach avoids the need to deploy a dedicated LLM. It allows for the use of existing APIs to access modern models, reducing resource costs and increasing the system's implementation efficiency.
In this paper, we examined a method for the automatic extraction and analysis of direct speech from texts using LLMs. The proposed approach enables the extraction of quotes from documents and the creation of networks of authors and concepts based on these direct quotes, opening new opportunities for analysis and research in various fields. The first step involves using LLM to identify quotes and authors, which automates the extraction of important information from texts. Subsequently, the models perform key concept extraction, helping to understand the main themes of 9 each quote and create a bimodal network of authors and concepts. This approach allows researchers to reveal connections between different authors based on shared concepts and interests, promoting a deeper analysis of the text’s themes. Network clustering, carried out by LLM, highlights groups of authors with shared concepts, thereby dividing them into thematic clusters. Using LLM for clustering provides flexibility in choosing methods and allows for the automatic generation of cluster names, reflecting their content and themes. The proposed technology can be integrated into broader information and analytical systems with two implementation options: either indexing the entire retrospective database for quote searching or operating in real-time for relevant documents without the need for archive indexing. Each of these approaches has its advantages and challenges, depending on the tasks and resources. Thus, utilizing LLM for automating direct speech extraction and analysing author concepts significantly speeds up the information processing, provides deep analysis of text data and creates new opportunities for research and intelligence gathering.
Citation: Kuzminskyi V, Lande D (2024). Automatic Extraction and Analysis of Direct Speech from Texts Using Large Language Model. J Theor Comput Sci. 10:228.
Received: 04-Nov-2024, Manuscript No. JTCO-24-34941; Editor assigned: 06-Nov-2024, Pre QC No. JTCO-24-34941 (PQ); Reviewed: 20-Nov-2024, QC No. JTCO-24-34941; Revised: 27-Nov-2024, Manuscript No. JTCO-24-34941 (R); Published: 04-Dec-2024 , DOI: 10.35248/2376-130X.24.10.228
Copyright: © 2024 Kuzminskyi V et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.