International Journal of School and Cognitive Psychology
Open Access
ISSN: 2469-9837
ISSN: 2469-9837
Research Article - (2015) Volume 2, Issue 2
Longitudinal dynamic models permit researchers to evaluate theoretical hypotheses of change involving two or more interrelated constructs over time. We used data from the Early Childhood Longitudinal Study-Kindergarten Class of 1998-99 (N=21,396) to assess change in children’s internalizing problem behaviors (IPB) and interest in reading (IR) from elementary school to middle school. Specifically, we applied Latent Difference Score Models (LDSMs) to evaluate: (a) dynamic structural change and (b) differential lead-lag relations between these two processes. We assessed the effect of each construct’s state at any given time on the changes in the other construct at a subsequent time. Our analyses indicate that children’s IR temporally preceded and predicted changes in IPB from third to eighth grade. The reverse pattern, however, was not supported. We showcase the utility of LDSMs as a tool for evaluation of dynamic changes and lead-lag relations across time.
Keywords: Longitudinal data analysis, Dynamic change modeling, Academic development
The analysis of change across time is an important objective of psychological inquiry. There are several methods of analyzing longitudinal change in the social sciences, including the prominent Repeated-Measures Analysis of Variance [1] and the more recently popularized data analytical methods of structural equation models (SEMs). Unfortunately, RM-ANOVA only provides information on mean differences, utilizes observed variables compound with measurement error, and requires several assumptions to be met in order to yield optimal results. Longitudinal SEM models such as Latent Autoregressive Models [2] and Latent Growth Curve Models [3,4], analyze stability and change of a hypothetical construct across time. Specifically, LAMs specify longitudinal lagged relations between latent variables of one or more constructs, and provide estimates on occasionto- occasion differences. LGCMs provide a summation of the overall latent trajectory across time. This model provides both group and individual differences about the sample’s starting value at the first time of measurement occasion and change across time points. Both, LAMs and LGCMs allow researchers to evaluate intra-individual change and identify inter-individual differences in intra-individual change over time [5].
However, both the LAM and LGCM have advantages and limitations. LAMs provide estimates on occasion-to-occasion measurements across time, whereas LGCMs offer information on the overall latent trajectory. A third model, introduced by McArdle and Hamagami [6], the Latent Difference Score Model (LDSM), combines the utilities of both the LAM and LGCM [7]. The general LDSM allows researchers to specify change among more than one system with a bivariate or multivariate version and evaluate how these systems relate to each other across time. Despite the advantages LDSMs offer, researchers rarely employ this model in their investigations. In this study, we demonstrate the advantage of utilizing bivariate LDSMs to analyze dynamic change of two processes and how they relate to each other across time, specifically by assessing lead-lag relations between these two systems.
Longitudinal models of change
A unique feature of LAMs is that they allow researchers to specify lagged relations among latent variables or hypothetical constructs across time. Specifically, latent variables at each occasion, with the exception of the first, are regressed onto the latent variable of the immediately previous occasion. This yields occasion-tooccasion regression parameters, known as auto-regressive or stability coefficients. Researchers may also specify lagged effects involving a series of processes with cross-lagged estimates. In such a case, the effect of one construct at a preceding time is lagged onto another construct at the current time [2].
In contrast to LAMs, LGCMs capture the overall growth trajectory and interindividual variability of a construct across time for multiple measurement occasions. In LGCMs, two latent variables are typically specified, an intercept, also known as an initial level, and a slope. With these latent variables, researchers are able to assess the average value of the initial measurement occasion (intercept) and growth trajectory (slope). An advantage of LGCMs is that individual differences at the first measurement occasion and change across time are also captured. That is, each unit (i.e. individual, event, case, etc.) in the sample can have a different growth trajectory represented by the variance of the intercept and slope [8,9] A detailed discussion of LAMs and LGCMs is provided by Joreskog [2] and Bollen and Curran [8], respectively.
LAMs and LGCMs offer several advantages over RM-ANOVA, a widely used method for analyzing change in the social and behavioral sciences [1] RM-ANOVA assesses differences between group means and variation between and within groups across time. Whereas only group effects (mean differences) can be evaluated with RM-ANOVA, LAMs and LGCMs assess mean differences and individual change. Moreover, both LAMs and LGCMs evaluate relations among latent variables instead of observed or manifest variables. Virtually all of psychological assessments contain error because constructs (e.g., depression, self-esteem, intelligence etc.) are measured with manifest or index variables, traditionally as part of a scale, intended to represent the construct. As a result, some of the variance in the manifest variable is residual variance. Residual variance represents variance that is not related to the construct under investigation and usually is simply unique item variance or measurement error due to human or calculation mistakes. Thus, RM-ANOVA analyzes relations between manifest variables that contain error. Conversely, both LAMs and LGCMs use latent variables where construct related variance and error variances have been separated allowing the analysis of true-scores. Therefore, by using latent variables instead of manifest variables, a more accurate representation of a longitudinal trajectory (i.e., depression development) is possible. Lastly, the LAM sand LGCM do not need to meet several assumptions required by RM-ANOVA method, such as sphericity of the covariance matrix and homogeneity of variance across measured time points. If these and other assumptions are not met, results produced from RM-ANOVA could be faulty.
From this discussion, it is possible to discern the fundamental advantages that LAMs and LGCMs offer for modeling change in a construct across time. However, as described earlier, LGCMs capture the overall growth and individual differences in the trajectory, but fail to provide any information about occasion-to-occasion changes across time, as possible with LAMs. Conversely, LAMs capture measurement-to-measurement changes, but fail to summarize growth of interindividual differences in intraindividual change across all multiple measurement occasions.
Because LAMs and LGCMs allow researchers to answer different theoretical questions, there may be instances across the social sciences where both approaches are needed to model change in a process. For instance, it is possible that for a particular process, regressing variable X at the previous time t-1 on X at the present time Xt1 will yield useful information about change; this relation can be evaluated with LAMs. It is also probable that for the same process, the collection of X on t regression is the key summary of change for the data; this description can be evaluated with LGCMs [10]. Therefore, a single overarching model is needed that allows researchers to capture both types of change in a process. A hybrid of the LAM and LGCM is the newly emerged Latent Difference Score Model (LDSM) introduced by McArdle and Hamagami [6].
Latent difference score models
The LDSM provides both occasion-to-occasion and latent growth curve estimates in an all-encompassing model. Accordingly, this model allows assessment of individual differences from occasion-to-occasion, as well as growth curve information as provided by the intercept (initial level) and slope mean and variance estimates at the latent level (free of measurement error). Thus, this model is often referred to as the dual change model. The general LDSM can model such changes among one (univariate), two (bivariate) or more developmental processes [11].
Bivariate latent difference score models
A bivariate LDSM, in which two processes are specified to influence each other, starts with the decomposition of two manifest variables Y and X for individual i at time t, Xit, Yit, into latent true scores y and x and a residual term ey and ex. Thus, manifest variables can be specified as:
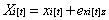
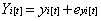
For each latent true score, with the exception of the first, for an individual i at time t xit, yit is a function of its previous status t-1 plus any change Δ that has occurred. Therefore, latent true scores can be written as:
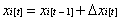
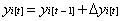
The change in true latent status between two adjacent time points defines the latent difference variable and can be specified as:
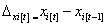
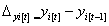
Therefore, a latent difference variable at time t, Δi(t), represents the difference in true latent status from its prior state t-1. Latent difference variables are the key feature of the general LDSMs, as change is directly analyzed through these variables, also known as latent difference scores (LDS). Once the LDS is defined, it can be written as a function of specific model components:
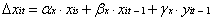
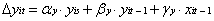
where αy and αx are the parameters representing the influence of the factor slope or the additive scores, yis and xis, for each construct, β is the auto-proportion change parameter that represents the proportional change of the same variable from the immediate preceding time t–1, and γ is cross-lagged parameter, representing the influence of the other variable at the previous time, t–1.
As mentioned, this model makes it possible to assess manifest variables Y and X trajectories for individual i across time t. This can be defined as a function of certain model components, such as the intercept (initial level) score or intercept, y0 and x0, and the accumulation of changes (i.e., changes in the unobserved variables Δy and Δx) up to time t, plus residuals, ey and ex. Therefore, this equation can be written as:
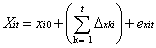
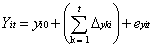
In summary, a bivariate LDSM captures the dynamic relations among two processes across time. The unique feature of any LDSM is the latent difference variables, and is a function of three components: an additive component, α, typically representing a constant influence on the process; the scores on the same variable at the previous occasion, β; and the scores on the other variable at the previous occasion, γ. This last component, the coupling parameter, represents effects from one variable at time t–1 that lead to changes in the other variable at the next occasion t, as the system unfolds over time. These coefficients (α, β, γ) are interpreted together, as together they represent the dynamics of the system.
In summary, LDSMs combine the benefits offered by LAMs and LGCMs, time-specific estimates and overall trajectory summary at the latent level, respectively. The general LDSM also allows researchers to specify change among more than one system and evaluate how these systems relate to each other across time. Despite the flexibility and advantages LDSMs offer, few studies have employed them in their investigation of dynamic change across time. Therefore, it is important to showcase the utility of LDSMs’ capability to (a) measure dynamic structural change of two processes and; (b) evaluate differential leadlag relations between these two systems over time.
Present Study
Our goal was to demonstrate the efficacy of bivariate LDSMs in modeling change using an empirical example. Extant research supports a strong interrelation between students’ internalizing problem behaviors (IPB) and academic interest, such as interest in reading (IR), across time [12-14]. Despite considerable research demonstrating a strong association between children’s IPB and IR, important questions remain unanswered. For example, it is unclear if these two processes develop in a meaningful dynamic way over time. Moreover, it is unknown whether children’s IPB temporally precedes and predicts changes in IR across school grades. Or, if the reverse holds, children’s IR temporally precedes and predicts changes in children’s IPB across school grades. Efforts to understand the interrelation of dynamic change between these two constructs has involved the use of traditional longitudinal models that fail to answer these questions. Using a nationally representative sample of school children from third to eighth grade, we used bivariate LDSMs to evaluate dynamic structural changes as well as lead-lag relations between children’s IPB and IR.
Participants
The data used for this study are from the “Early Childhood Longitudinal Study, Kindergarten Class of 1998-1999 (ECLS-K)”, a project aimed at examining educational, physical, cognitive and social development among children across time [15,16]. The ECLS-K data included a nationally representative sample of 21,396 children (10,950 males and 10,446 females) from diverse racial/ethnic and socioeconomic backgrounds. Approximately 55% of children self-reported non- Hispanic White, 15% non-Hispanic Black, 18% Hispanic, 6% Asian, and 3% reported being other. The average family household income for this sample was $52,040 (SD=$56,040), and, the median was about $40,000. The average child’s age during the first measurement occasion (kindergarten) was 5.70 (SD=0.36).
Internalizing problem behaviors
To assess IPB, the Self-Description Questionnaire I (SDQI) for preadolescents was administered to children in the first and second times of measurement occasion, third and fifth grades, respectively [17]. This scale contained four items and children were asked to selfrate IPB using a 4-point likert scale (“1=not at all true” to “4=very true”). This scale was composed of the following items: “I feel angry when I have trouble learning,” “I worry about taking tests,” “I worry about doing well in school,” and “I worry about finishing my work”. At the third time point, eighth grade, the Self-Description Questionnaire II (SDQII) for adolescents was used to assess IPB [18]. For this scale students were asked to rate their IPB using the same four items and 4-point response scale as that of the SDQI. The alpha reliabilities for the IPB scale for students in third, fifth and eighth grades were 0.71, 0.72 and 0.70, respectively.
Interest in readingThe SDQI was also administered to children at the first (third grade) and second (fifth grade) time point to assess their IR [17]. This scale contained four items and children were asked to rate their IR using a 4-point likert scale (“1=not at all true” to “4=very true”). This scale was composed of the following items: “I like reading”, “I am interested in reading,” and “I cannot wait to read each day,” and “I like reading long chapter books”. The same SDQII was used to evaluate IR at the third time point [18]. For this two item scale students were asked to rate their interest in reading using the same 4-point response scale as that of the SDQI. The two items in the SDQII were: “I like reading” and “I enjoy doing work in reading”. The alpha reliabilities for the IR scale for students in third, fifth and eighth grades were 0.80, 0.82 and 0.80, respectively.
Factorial invariance prior
To analyzing change in children’s IPB and IR across time, factorial invariance was assessed. Establishing factorial invariance consists of a hierarchy of levels that include: configural, weak, strong and strict invariance, which are evaluated in a measurement model [9,19-21]. Establishing factorial invariance is required prior to modeling change when manifest variables are used to represent latent constructs, especially when modeling latent change is concerned. Establishing factorial invariance ensures that the same construct under investigation is being measured across time [22,23].
Latent difference score models
Three bivariate LDSMs were carry out to evaluate the dynamic changes and lead-lag relations among IPB and IR across grades. Model 1 assessed the effect of each construct’s immediately preceding time of measurement latent true score on the other construct latent difference score. Model 2 assessed the effect of IPB’s immediately preceding time of measurement latent true score on IR’s latent difference score, or the influence of IPB on IR’s time to time change. Model 3 assessed the effect of IR’s immediately preceding time of measurement latent true score on IPB’s latent difference score, or the influence of IR on IPB’s time to time change. For all three models, lagged effects between IPB and IR across time were represented by coupling coefficients, where change in IPB latent difference score was regressed on IR’s latent true score at the previous point in time, and change in IR latent difference score was regressed on IPB’s latent true score at the previous point in time.
Therefore no additional analyses were run to investigate missing data. FIML assumes that measurement occasions for an individual are associated across time, as a result, this estimator utilizes all available data from the earlier to later measurement occasions to estimate model parameter and residual values. Therefore, it was determined that FIML was the appropriate method to estimate analyses.
Estimation and Model fit
All models were carried out in Mplus 6.1 using Full Information Maximum we considered multiple indexes. The statistical model fit test Chi- Square (χ2) was assessed for each model; however, a limitation of this test is its sensitivity to sample size. In large samples, about 5,000 cases, the χ2 can be unsuccessful in detecting small statistical differences between the implied and observed model in data [24]. Therefore, the absolute model fit index Root Mean Square Error of Approximation [25], and relative fit indices, such as Comparative Fit Index [26]. And Tucker-Lewis Index [4] was also utilized to evaluate model fit.
Table 1 summarizes the means, standard deviations and correlations for each construct analyzed in this study. Children’s IPB and IR scores ranged from 1 to 4 (4=high). The mean of children’s IPB composite scores showed a negative trend from third grade to eighth grade. For instance, in third grade children had an IPB mean of 3.25 (SD=0.68), in fifth grade the mean decreased to 3.02 (SD=0.72) and once more in eighth grade, 2.76 (SD=0.44). A similar trend is observed for the mean of children’s IR composite scores. In third grade, the mean was 4.00 (SD=0.75), in fifth grade it dropped to 2.97 (SD=0.85) and again in eighth grade 2.34 (SD=0.92) (Table 1). A zero order-correlation matrix for IPB composite scores revealed a strong correlation between third and fifth grade IPB scores (r=0.41), and moderate correlations between fifth grade and eighth (r=0.32), as well as between third and eighth grade (r=0.19). As for IR composite scores, a zero-order correlation matrix revealed a strong correlations between third and fifth grade IPB scores (r=0.44), and fifth grade and eighth (r=0.45). A medium-sized correlation was found between third and eighth grade IR composite scores (r=0.26). Also, large correlations were found between IPB and IR composite scores in third grade (r=0.64), fifth grade (r=0.71) and eighth grade (r=0.43). A random subsample of 50 children was used to create a scatterplot of these data. Figures 1 and 2 reveal nonlinear trajectories for children’s IPB and IR across three time points, third, fifth and eighth grade. Most importantly, the descriptive statistics and graphs reveal substantial differences between individuals across time.
| Third Grade | Fifth Grade | Eight Grade | |
|---|---|---|---|
| Mean (SD) | Mean (SD) | Mean (SD) | |
| IPB | 3.25(0.68) | 3.02(0.72) | 2.76(0.84) |
| 1.0 | |||
| 0.41 | 1.0 | ||
| 0.19 | 0.32 | 1.0 | |
| IR | 4.00(0.75) | 2.97(0.85) | 2.34(0.92) |
| 1.0 | |||
| 0.44 | 1.0 | ||
| 0.26 | 0.45 | 1.0 |
Table 1: Means (SDs) and Zero-Order Correlations for Perceived Competence in Reading and Interest in Reading Composite Scores across Third, Fifth and Eighth Grade.

Figure 1: A random subsample (n=50) of internalizing problem behaviors scores (scores range 1 - 4) across three time points (1=third grade, 2=fifth grade and 3=eighth grade).

Figure 2: A random subsample (n=50) of interest in reading scores (reading scores, range 1 - 4) across three time points (1=third grade, 2=fifth grade and 3=eighth grade).
| Configural nvariance |
Weak Invariance |
Strong Invariance |
Strict Invariance |
|
|---|---|---|---|---|
| Internalizing Problem Behaviors Scale | ||||
| / df fit | 620/43 | 647/49 | 804/55 | 1691/63 |
| ∆/ ∆df fit | --- | 27/6 | 157/6 | 887/8 |
| RMSEA (CI) | .03(0.028, 0.032) | .03(0.027, 0.031) | .03(0.028, 0.032) | .04(0.04, 0.043) |
| CFI | .98 | .98 | .97 | .94 |
| TLI | .97 | .97 | .97 | .94 |
| Interest in Reading Scale | ||||
| df fit | 497/26 | 806/30 | 1037/34 | 2049/39 |
| ∆∆df fit | --- | 309/4 | 231/4 | 1012/5 |
| RMSEA (CI) | .04(0.03, 0.04) | .04(0.04, 0.04) | .05(0.04, 0.05) | .06(0.06,0.06) |
| CFI | 0.99 | 0.99 | 0.98 | 0.96 |
| TLI | 0.99 | 0.98 | 0.98 | 0.96 |
| Note. RMSEA value and RMSEA 90% Confidence Interval (CI) are rounded to the third decimal point for accuracy; symbol=indicates item constrained to equality across time. All estimated values were statistically significant at 0.01 level. | ||||
Table 2: Factorial invariance tests.
Internalizing problem behaviors
Factorial invariance must be established before measuring longitudinal change in order to ensure that any change that is captured takes place at the latent level. Therefore, configural, weak, strong, and strict factorial invariance were tested for IPB across third, fifth and eighth grade (Table 2). Configural invariance or non-metric invariance was met for this scale as there were four items loading on each factor at all three time points. This initial model served as a baseline to test factorial invariance in subsequent models across time. A significant change in chi-square from the configural to the weak factorial invariance model was found, p<0.001. However, examination of the practical fit indices indicated that the values for RMSEA, CFI and TLI from this test were the same as those from the configural invariance model. Based on these fit statistics, strong factorial invariance was evaluated. A test for strong factorial invariance produced a significant change in chisquare, p<0.001. Again, assessment of the practical fit indices indicated that such indices did not change. Once more, the RMSEA and TLI values from the strong factorial invariance test remained the same as those of the weak invariance’s test model and only a small change in the CFI occurred. Next, strict factorial invariance was evaluated. A test for strict factorial invariance produced a significant change in chisquare, p<0.001. Additionally changes in RMSEA, CFI and TLI were found, indicating lack of strict factorial invariance. In order to establish factorial invariance across time, at least the third level of factorial invariance, strong factorial invariance, must be met. Based on these analyses it was determined that strong factorial invariance was tenable for the IPB construct
Interest in reading
Results from this test are summarized in the lower part of Table 2. Configural invariance for this IR scale was questionable, as there were four items loading on each factor at time one and two, but only two items loading on the third factor at time three. As was the case for IPB, examination of fit indexes at each step suggested that strong factorial invariance was plausible for IR construct.
After establishing factorial invariance for both IPB and IR across time, corresponding individual items for each scale were averaged to create a composite score to represent the construct at each measurement occasion. These new composite scores were employed to assess change in the LDSMs of subsequent analyses.
Bidirectional relations between IPB and IR
Model 1 assessed the effect of each constructs’ immediately preceding time of measurement latent true score on the other construct latent difference score (Table 3). Model fit indices revealed a significant chi-square index (χ2=286), most likely as a result of the large sample size. However practical fit indices indicated acceptable fit (RMSEA=0.06 [.05, 0.06], CFI=0.98, TLI=0.96) suggesting that interpretation of the model is close. According to this model, the unobserved latent means or intercept means (μ0) for IPB and IR were 3.25 and 3.30, respectively. Each unobserved latent mean represents the average IPB (μ0=3.25) and IR (μ0=3.30) score at the first time of measurement (third grade) across all children analyzed. There was a negative additive mean effect or slope (μ0) for both IPB and IR (-.93 and -.47, respectively), representing a constant amount of change per measured occasion. Model 1 estimates also suggest that change in IPB latent difference scores is influenced by both preceding IPB and IR scores. For instance, auto-proportion change coefficients indicate positive lagged effects on IPB latent difference scores from its own preceding score (β=0.84), as well as a negative coupling from prior IR latent true scores (γ=-.58) on IPB latent difference scores. Change in IR latent difference scores is also influenced by both preceding IR and IPB scores. For instance, autoproportion change coefficients indicate positive lagged effects on IR latent difference scores from its own preceding score (β=0.12), as well as a negative coupling from prior IPB latent true scores (γ=-.03) on IR latent difference scores. Model 1 specified a bidirectional relation between IPB and IR across grades, specifically, testing dual change effects within each construct. Results indicated a dynamic interrelation of IPB and IR across time. Next, the effect of IPB on IR change was evaluated.
IPB Predicting and determining IR change
Model 2 assessed the effect of IPB’s immediately preceding time on IR’s latent difference score. Model 2 fit worsen compared to Model 1, (χ2=643, RMSEA=0.08 [0.07, 0.08], CFI=0.97, TLI=0.94) suggesting that interpretation of the model is poor. Model 2 estimates indicate that the unobserved latent mean or intercept mean (μ0) for IPB and IR were 3.22 and 3.29, correspondingly. There was a negative additive mean (μ0) for both IPB and IR (α=-0.49 and -0.24, respectively), representing a constant amount of change per measurement occasion. Auto-proportion coefficients indicate positive effects on IPB latent difference scores from its own preceding score (β=0.13). Model 2 results suggest that change in IPB is positively influenced by a latent additive process and a lagged relation from its own preceding score. Change in IR latent difference scores is influenced by both IR and IPB scores. Auto-proportion coefficients indicate positive lagged effects on IR latent difference scores from its own preceding score (β=0.37), and negative coupling from prior IPB latent true scores (γ=-0.34) on IR latent difference scores. Model 2 specified a cross-lagged effect of IPB on IR across grades. Although model fit indices were poor for this model, results indicated that change in IR across grades is driven by a latent additive process, IR’s and IPB previous state of measurement. Next, the effect of IR on IPB change was evaluated.
IR predicting and determining IPB change
Model 3 assessed the effect of IR’s immediately preceding time of measurement latent true score on IPB’s latent difference score. Model fit indices were strong (χ2=286, RMSEA=0.05 [0.04, 0.05], CFI=0.99, TLI=0.97) suggesting that interpretation of the model is close. Estimates from this model indicate that the unobserved latent mean or intercept mean (μ0) for IPB and IR were 3.25 and 3.30, correspondingly. There was a negative additive mean for both IPB and IR (α=-0.94 and -0.51, respectively), representing a constant amount of change per measurement occasion. Change in IPB is influenced by both IPB and IR scores. Auto-proportion coefficients indicate positive lagged on IPB latent difference scores from its own preceding score (β=0.85) and negative coupling from prior IR scores (γ=-0.59). Furthermore, auto-proportion coefficients indicate positive lagged effect on IR latent difference scores from its own preceding score (β=0.11). Model 3 results suggest that change in IR is positively influenced by a latent additive process and a lagged relation from its own preceding score.
This paper described LDSMs as a longitudinal modeling approach for examining dynamic changes and lead-lag relations among multivariate processes that unfold over time. LAMs and LGCMs are longitudinal modeling options for researchers interested in assessing change of a construct. However, a more advantageous method for modeling dynamic change across time is with LDSMs. The key advantage of LDSMs is that they allow researchers to assess multiple influences of change over time, such as, autoregressive effects, crosslag effects and constant growth at the latent level in one overarching model.
| Model 1 | Model 2 | Model 3 | ||||
|---|---|---|---|---|---|---|
| IPB | IR | IPB | IR | IPB | IR | |
| Fixed parameters | ||||||
| Initial level mean µ0 | 3.25 (0.006) | 3.30 (0.006) | 3.22 (0.006) | 3.29 (0.007) | 3.25 (0.006) | 3.30 (0.006) |
| Slope mean α | -0.93 (0.12) | -0.47 (0.08) | -0.49 (0.06) | -0.24 (0.08) | -0.94 (0.12) | -0.51 (0.04) |
| Proportional change β | 0.84 (0.09) | 0.12 (0.04) | 0.13 (0.02) | 0.37 (0.03) | 0.85 (0.09) | 0.11 (0.01) |
| Coupling γ | -0.58 (0.06) | -0.03 (0.06) | 0.00* | -0.34 (0.04) | -0.59 (0.06) | 0.00* |
| Variance parameters | ||||||
| Initial Level σi2 | 0.20 (0.01) | 0.27 (0.007) | 0.20 (0.006) | 0.27 (0.007) | 0.20 (0.006) | 0.27 (0.007) |
| Slope variance | 0.05 (0.01) | 0.01 (0.001) | 0.02 (0.001) | 0.21(0.002) | 0.05 (0.01) | 0.01(0.001) |
| Residual σe2 | 0.29 (0.004) | 0.35 (0.005) | 0.30 (0.004) | 0.35 (0.005) | 0.29 (0.004) | 0.35 (0.005) |
| σis | -0.06 (0.008) | -0.03 (0.004) | -0.04 (0.004) | -0.04 (0.005) | -0.06 (0.008) | 0.04(0.004) |
| ρis | -0.62 | -0.56 | -0.69 | -0.57 | -0.62 | -0.57 |
| Cov(PCRi, IRi[ρ]) | 0.19 (0.005) [0.83] | 0.19 (0.006) [0.82] | 0.19 (0.005) [0.83] | |||
| Cov(PCRi, IRs,[ρ]) | -0.02 (0.005) [-0.37] | -0.007 (0.005) [-0.11] | -0.02 (0.003) [-0.41] | |||
| Cov(PCRs, IRi, [ρ]) | -0.01 (0.006) [-0.11] | -0.04 (0.004) [-0.54] | -0.01 (0.006) [-0.11] | |||
| Cov(PCRs, IRs,[ρ]) | 0.003 (0.003) [0.12] | 0.006 (0.001) [0.34] | 0.005 (0.001) [0.18] | |||
| Model Fit Statistics | ||||||
| χ2 (df) | 286 (6) | 643 (7) | 286 (7) | |||
| BIC | 140914 | 141262 | 140905 | |||
| RMSEA | 0.06 (0.05, 0.06) | 0.08 (0.07, 0.08) | 0.05 (0.04, 0.05) | |||
| CFI | 0.98 | 0.97 | 0.99 | |||
| TLI | 0.96 | 0.94 | 0.97 | |||
| Note. IPB: Internalizing problem behaviors; IR: Interest in reading; Cov: Covariance; 0.00*fixed at 0. Entries are estimates and standard errors (in parentheses). Ndata points=14,832. Range for all variables is 1 – 4. | ||||||
Table 3: Parameter Estimates (Standard Errors) and Fit Statistics from Bivariate LCS Models.
This study used longitudinal data from a nationally representative study to investigate change in children’s IPB and IR from third to eighth grade by applying LDSMs. Results showed that factorial invariance could be assumed for both constructs. Next, three different models were run to investigate dynamic structural change and leadlag relations between IPB and IR. Model 1 specified a bidirectional relation between IPB and IR across time. Estimates indicated dynamic interactions between these two processes, specifically, each construct changed as a function of its own and the other construct’s preceding state. Moreover, model fit indices were acceptable, indicating that this model was a good representation of these data. Model 2 focused on the influence of IPB’s previous state on IR change. Model fit indices worsen, indicating that this model was not a good representation of these data and that IPB’s most likely does not precede or help predict changes of IR among this sample across time. Finally, Model 3 evaluated the influence of IR’s previous state on IPB change. According to Model 3 estimates and fit indices, IR precedes and predicts changes in IPB across time and this model represents these data strongly. Comparing fit indices across all three models revealed that Model 3 is the best fitting model for these data. Therefore, for this sample IR is a leading indicator of change in IPB from third to eighth grade. Evaluation of dynamic change and lead-lag relations are just some of the analyses that can be conducted with LDSMs.
Applications of LDSMs and future research
In general, LDSMs can be used to study a broad range of longitudinal latent changes. For instance, these models allow researchers to combine the identification of change in multiple variables with the underlying dynamics among all processes. For this reason, LDSMs are helpful in examining hypotheses that involve interrelations among several constructs together with changes in those constructs over time. Additionally, LDSMs permit researchers to detect sequences among variables over time. This modeling capability is especially useful when analyzing developmental processes that do not unfold continuously, as in the presence of developmental discontinuities. Researchers can also assess whether external variables predict the dynamics underlying a construct. For example, to examine whether age predicts change in IR and/or IPB, each latent difference variable could be regressed onto the age of participants. Ultimately, the decision of how to specify LDSMs depends on the theory and goals of the researcher. Overall, LDSMs provide a longitudinal method for testing factorial invariance and flexibility to address a number of different research questions about dynamic changes compared with more traditional longitudinal models.